Guillermo Ernesto Canales Mancia
Kenny Guadalupe Marroquín Paniagua
En la
actualidad todas las empresas protegen su información de muchas maneras, una de
las más comunes es almacenarlas en la nube, por su facilidad de acceso, la
capacidad de administración y por qué es uno de los medios mas económicos que
existen, hay otro sin fin de opciones como los RAID (hace referencia a un sistema de almacenamiento que usan
múltiples discos
duros o SSD entre los que se distribuyen o replican los datos),
los Backups de información, las configuraciones de alta disponibilidad. Pero, cualquiera
que sea el medio de protección que se utilice para no perder información
importante, puede verse afectada por cualquier desastre ya sea natural o
causado por la mano del hombre...
Los desastres están a la orden
del día, por eso las empresas deben mantener un plan emergente ante las
amenazas de un desastre con el objetivo de que si sucede algún percance podamos
solucionarlo lo mas rápido posible. La
planificación implica configurar un sitio remoto en espera de que puede
hacerse cargo de aplicaciones y operaciones importantes dentro de un plazo
razonable, si ocurre un desastre.
Un buen plan de Recuperación es una meta difícil de alcanzar. El principal
obstáculo que surge es el hecho de que no se sabe muy bien qué catástrofes está
planeando. Sin embargo se debe estar
listo para responder rápidamente ante los problemas y recuperarse del desastre.
Además se debe determinar el tiempo de inactividad permitido para el
proceso de recuperación. Un plan bien diseñado salva su negocio de un desastre
inminente.
La planificación para desastres
es fácil de olvidar para un administrador de sistemas, con tanto trabajo y
presión no es agradable y siempre
pareciera que hay algo más importante que hacer. Sin embargo, dejar pasar la
planificación para desastres es una de las peores cosas que un administrador de
sistemas puede hacer. Si nos vemos afectados por cualquier fallo el tiempo de
trabajo se detiene..
El tiempo de inactividad es caro
y esto a consecuencia de:
- Ventas perdidas
- El costo de tiempo y materiales para reparaciones de hardware
- Reducción de reputación de servicio al cliente y la fiabilidad
- La pérdida de la buena voluntad y reputación entre los clientes
- empleados inactivos y pérdida de productividad
Si se compara el costo de la inactividad con la de su
protección de los datos, el costo de la protección de datos no parece caro.
Son muchos los desastres que
pueden ocurrir en un centro de datos los más comunes son:

Los desastres ocurridos dentro de
un data center pueden ser a causas naturales o artificiales, si bien hay
algunas que no se pueden evitar pero si se pueden crear medidas preventivas
para evitar daños mayores, entre estas causas tenemos:
Fallas ambientales:
Los
problemas pueden ocurrir aun cuando el hardware se está ejecutando
perfectamente y aunque el software esté configurado de la forma adecuada. Los
problemas más importantes que ocurren fuera del sistema mismo tienen que ver
con el ambiente físico en el cual reside el sistema.
Los
problemas ambientales se pueden desglosar en cuatro categorías:
- Electricidad
- Aire acondicionado
- Cortes de energía en tiempo prolongados
- Ataques terroristas
- Tiempo y el mundo exterior:
- Lluvias
- Incendios
- Terremotos
Es fácil identificar Cuando falla
el hardware pues el trabajo se detiene,
lo que es difícil es determinar cual fue la causa del problema, este tipo de
fallas suelen ser de los mas caros en las empresas pues la solución debe ser
pronta y adecuada.
Este tipo de falla es la que mas
se debe prever, algunas de las
soluciones pueden ser:
1. Mantener partes
adicionales de hardware
En este caso es importante tener el repuesto del hardware
que se requiere, para ello el administrador debe tener la habilidad de
planificar el tipo de hardware que debe mantener para casos de emergencia, este
tipo de soluciones requiere dos cosas:
· Alguien
está en el sitio con suficientes habilidades para diagnosticar el problema,
identificar la parte defectuosa y remplazarla.
- Está disponible un repuesto para el hardware defectuoso.
Estas habilidades se obtienen con
la experiencia de haber trabajado con
hardware con anterioridad.
Mantener hardware almacenado es
algo muy delicado pues deben considerarse ciertos factores entre ellos:
- Tiempo máximo permitido fuera de servicio
- La habilidad requerida para hacer la reparación
- El presupuesto disponible para los repuestos
- Espacio de almacenamiento requerido para los repuestos
- Otro hardware que podría utilizar el mismo repuesto
Todo debe estar bien planificado
para no incurrir en gastos innecesarios a la empresa, evitando q la solución
prevista sea mas cara que el desastre mismo. Debe considerarse el tipo de
repuesto, la ventaja de mantener ese repuesto, las condiciones en que debe
mantenerse y si en realidad será efectivo.
1. Contratos de servicios
Los contratos de
servicios pasan el problema de las fallas de hardware a alguien más. Lo único
que necesita hacer es confirmar que ha
ocurrido una falla y que no parece estar relacionado a un problema de software.
Simplemente hace la llamada y alguien
más aparece para encargarse de que las cosas estén en funcionamiento otra vez
Parece muy simple.
Pero hay cosas que se deben considerar para utilizar este tipo de solución
- Horas de cobertura
- Tiempo de respuesta
- Partes disponibles
- Presupuesto disponible
- Hardware cubierto
Tomando en
cuenta que los centros de datos trabajan las 24 horas del día, los 7 días de la
semana, las fallas pueden ocurrir en cualquier momento y el resultado puede ser
menor si se resuelve inmediatamente por tanto se necesita un servicio emergente
que brinden asistencia a cualquier hora. Un servicio de este tipo es casi
imposible a menos que este dispuesto a pagar bien. Saldría carísimo, la mayoría
de las empresas que brindan este servicio tienen horarios que cumplir, si
quiere resultados oportunos usted deberá brindar un poquito de trabajo. Además
se debe considerar el tiempo que tardaran en presentarse luego de su llamada.
Fallas de software
Las fallas de software pueden
ocurrir en dos maneras:
1.
Fallas de sistemas operativos:
En este tipo de
fallas el sistema operativo es el responsable de la suspensión de servicio y
puede deberse a: caídas del sistema Colgarse o bloquearse Este tipo de
fallas puede ser devastadora para la producción,
2.
Fallas de aplicaciones:
A diferencia de
las fallas del sistema, las fallas de las aplicaciones pueden ser más limitadas
en el ámbito de lo que dañan. Dependiendo de la aplicación específica, una sola
aplicación que esté fallando puede afectar solamente a un usuario. Por otro
lado, si se trata de una aplicación de servidor que está sirviendo a una gran
población de aplicaciones clientes, las consecuencias de la falla serían mucho
más extensas.
Las fallas de las
aplicaciones, igual que otras fallas del sistema, pueden ser causadas por
caídas o bloqueos; la única diferencia es que aquí es la aplicación la que se
está guindando o fallando.
Ante los problemas
de software la herramienta de primer nivel para la solución de este problema es
la documentación, ya que tienen la información necesaria para resolver muchos problemas.
Errores humanos.
Las computadoras son realmente perfectas. La razón detrás
de esta afirmación es que si usted profundiza lo suficiente, detrás de cada
error computacional encontrará el error humano que lo causó. En esta sección se
exploran los tipos de errores humanos más comunes y sus impactos.
Cuando las
aplicaciones son usadas inapropiadamente, pueden ocurrir varios problemas:
- Archivos sobrescritos inadvertidamente
- Datos incorrectos utilizados como entrada a una aplicación
- Archivos no claramente nombrados u organizados
- Archivos borrados accidentalmente
Todo esto puede ser causa de no
seguir con los procedimientos establecidos, o se realizan los errores durante
estos procedimientos, es decir puede ser causa de descuidos durante la
ejecución de los procesos
Los administradores de sistemas
ven el resultado de estos errores a diario, especialmente de los usuarios que
juran que no cambiaron nada, simplemente la computadora dejo de funcionar. El
usuario que afirma esto usualmente no recuerda qué fue lo que hizo.
Errores cometidos durante el
mantenimiento
Los administradores de sistemas
ven el resultado de estos errores a diario, especialmente de los usuarios que
juran que no cambiaron nada, simplemente la computadora dejo de funcionar. El
usuario que afirma esto usualmente no recuerda qué fue lo que hizo.
Ud. debe ser capaz de recordar
los cambios que realizó durante un mantenimiento si quiere ser capaz de
resolver los problemas rápidamente. Un verdadero proceso del control del cambio
no es realístico para los cientos de cosas que se hacen durante un día. ¿Qué se
puede hacer para seguir las 101 cosas que un administrador de sistemas realiza
diariamente?
Errores de Servicio Técnico
En ocasiones las personas que se
cree deberían ayudar a mantener sus sistemas funcionando, son los que complican
más las cosas. Y es por el hecho de que
cualquiera que esté trabajando en una tecnología por alguna razón, arriesga el
hacer esa tecnología inoperable. El mismo efecto es en el trabajo cuando los
programadores reparan un fallo pero terminan creando otro.
En este caso, el técnico falló en
diagnosticar el problema correctamente y realizó una reparación innecesaria o
el diagnóstico fue correcto, pero la reparación realizada no se llevó a cabo
bien. Puede ser que la parte misma remplazada estaba defectuosa, o que no se
siguió el procedimiento adecuado cuando se realizó la reparación.
Aunque el diagnostico haya sido el
correcto en muchas ocasiones cuando se repara algo no se tiene el cuidad y se
daña otra, esto a consecuencia de que no era el adecuado, hay incompatibilidad
de hardware o software o simplemente fue un descuido, por tanto antes que el
técnico se retire se debe verificar que todo este funcionando correctamente.
Creación, Evaluación e Implementación de un Plan de
Recuperación de Desastres
Planear como recuperar los datos
puede ser una tarea difícil, los desastres pueden dejar una huella imborrable
si no se toman las medidas necesarias para salir de ese problema.
La recuperación de desastres es
la habilidad de recuperarse de un evento que impacta el funcionamiento del
centro de datos de su organización lo más rápido y completo posible. El tipo de
desastre puede variar, pero el objetivo final es siempre el mismo.
Los centros de datos siempre
deben tener una copia de seguridad y respaldo, estos con un documento detallado
de que hacer en casos de desastres, este puede ser vital para la recuperación del data
center.
Para planear como recuperarse de
un desastre puede seguir las siguientes fases, el resultado dependerá de la
gravedad del asunto:
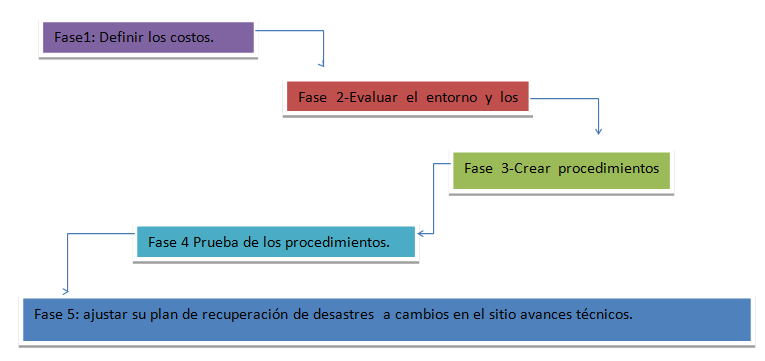
1.
Definir Costos:
Esto es más fácil decirlo que
hacerlo. Todo el mundo aprecia la necesidad de un plan de recuperación de
datos, pero los beneficios se obtienen
sólo durante un desastre. ¿Y, si
no ocurre el desastre? Todo el dinero empleado sería en vano. La gente va a señalar que
muchas de esas causas a ellos no les afectaran. El segundo problema es que un
plan de recuperación de desastres por lo
general no parece tan urgente.
Usted debe tomar un enfoque
diferente. Vender un programa de recuperación de desastres seria como vender
seguros de vida. La mayoría de las personas tienen un seguro de vida, ya que
les da tranquilidad saber que si algo llegara a suceder su familia no estaría
en problemas financieros.
Si su negocio tiene un desastre y
se enfrenta a tiempos de inactividad inesperado, su empresa puede utilizar el
plan de recuperación de desastres para recuperar rápidamente aplicaciones de y
servicios vitales, evitando así el alto costo asociado con el tiempo de
inactividad.
Esto nos lleva a la segunda razón
por qué las grandes empresas a nivel mundial necesitan un Plan de recuperación
de desastres.
Al determinar el costo por hora
de tiempo de inactividad, las empresas consideran varias cosas como la pérdida
de productividad de los empleados, pérdida de ventas, el costo de tratar de
volver a crear los datos, y la confianza del cliente. Comparar la estimación de
costo del tiempo de inactividad y los costos de la implementación de un plan de
recuperación de desastre. Es muy probable que el costo del tiempo de
inactividad sea mucho mayor que el coste de la protección de los datos.
Para la aprobación de este plan
La alta dirección debe sentirse comprendido. Su solución debe abordar estas
preocupaciones:
- La recuperación de desastres es importante, pero ¿quién lo hará? Se trata de un programa que no genera ingresos.
- ¿Cuánto costará?
- Será suficiente un plan de recuperación de desastres?
Estas preocupaciones no hacen más
fácil la planificación, pero una vez se obtiene la aprobación esta listo para
la siguiente fase.
Fase 2: Evaluación de Riesgos y
Medio Ambiente Existente
Debe realizar una lista de los
desastres a los que puede ser susceptible como terremotos, incendios, virus,
hackers, errores del operador, empleados, hardware o software, y los desastres
naturales. Estos son los que debería recibir más atención. Una vez finalizada
la lista deberá asignar el impacto de
los desastres para el negocio y operaciones.
Identificar las áreas de negocio
que sufriría el mayor daño financiero en caso de un desastre. Por último,
reunir un equipo y asignar responsabilidades a cada miembro.
Fase
3: Crear Procedimientos para la recuperación de desastres
En esta fase, se establecerá el
procedimiento actual para las secuelas de un desastre. Esta fase se llevará la
mayor parte del trabajo y del tiempo. El procedimiento debe documentar cómo hacer frente a los
diferentes errores que pueden devastar
la infraestructura de TI(Tales como la pérdida completa de los servidores, los
datos, routers, puentes, comunicación
Enlaces, etc.) .
Al buscar la manera de hacer
frente a estas pérdidas, se dará cuenta de que hay soluciones alternativas. La configuración
actual no puede tener derechos de emisión por fallas en el sitio o un corte
completo de la configuración. Antes de determinar y documentar un proceso de recuperación
de desastres, debe rediseñar las configuraciones que no tienen redundancia.
También debe crear una lista de
comprobación para verificar si todo ha sido restaurado a su estado normal.
Al final, el plan de recuperación
de desastres debe ser completo, integral
y actual. Por "Completo", se refiere a que debe ser lo suficientemente detallada para
incluir cada etapa de recuperación.
En momentos de estrés, y cuando
las personas encargadas no están presentes, debe servir como un paso a paso de
cómo hacerlo. Debe ser integral e incluir todos los elementos dentro del centro
de datos y por fuera, todos los componentes críticos, y todas las unidades de
negocio.
Fase
4: Prueba de los procedimientos
La prueba es la forma más
práctica de encontrar fallas en el programa de recuperación de desastres debe
resolver antes de que ocurra un desastre. Todo queda en ridículo si su programa de recuperación de desastres no
funcionó cuando se necesitaba. Sin embargo, las pruebas de un plan de
recuperación de desastres es caro. Los
efectos se han generalizado y se necesita tiempo para todos, pero es la única
manera de descubrir los defectos y asegurarse de que funcionara cuando se
necesite.
Hay varios requisitos previos
para una prueba. En primer lugar, elaborar un plan de pruebas y decidir la frecuencia de las pruebas. Esto depende de
la rotación de personal y técnicos, cambios en el procedimiento de recuperación
de desastres, el sistema y la red. Es difícil o imposibles recrear un verdadero
desastre. Estos actos pueden ser peligrosos para s el bienestar de los trabajadores. Si se Decide sobre un
simulacro de desastre que no perjudique a nadie. Deberá ser notificada. No es
necesario informar a todos de la próxima prueba. Sólo algunos supervisores,
gerentes y ejecutivos de la compañía necesitaran saber, ya que el elemento de la sorpresa está más cerca de la
realidad. Pero los que saben deberán controlar el estrés emocional, los conflictos
y el caos. Finalmente idear una manera de medir el éxito de cada prueba.
Fase
5: Ajustar su plan de recuperación de desastres
a cambios y Los avances tecnológicos.
Habrá nuevos servidores y
aplicaciones añadidas al plan recuperación de desastres. Sea consciente de las
últimas tendencias tecnológicas, especialmente aquellas que aumentan la eficiencia
de los procedimientos. El tiempo para
recuperarse de un desastre es fundamental.
Para establecer lo que se debe
hacer en caso de desastres, Los documentos deben ser lo suficientemente simple para
que un empleado nuevo pueda comprender y actuar como se debe.
El diseño de una arquitectura
tolerante a desastres debe tomar varias medidas para asegurar que los
diferentes aspectos de su negocio están protegidos.
Un sitio de respaldo es vital,
sin embargo es inútil sin un plan de recuperación de desastres. Un plan de
recuperación de desastres indica cada faceta del proceso de recuperación,
incluyendo (pero no limitado) a:
- Los eventos que denotan posibles desastres
- Las personas en la organización que tienen la autoridad para declarar un desastre y por ende, colocar el plan en efecto
- La secuencia de eventos necesaria para preparar el sitio de respaldo una vez que se ha declarado un desastre
- Los papeles y responsabilidades de todo el personal clave con respecto a llevar a cabo el plan
- Un inventario del hardware necesario y del software requerido para restaurar la producción
- Un plan listando el personal a cubrir el sitio de respaldo, incluyendo un horario de rotación para soportar las operaciones continuas sin quemar a los miembros del equipo de desastres
- La secuencia de eventos necesaria para mover las operaciones desde el sitio de respaldo al nuevo/restaurado centro de datos
Regreso a la normalidad
Se
deben hacer y entregar los últimos respaldos desde el sitio de respaldo al
nuevo centro de datos. Después de almacenarlos en el nuevo hardware, se puede
reactivar la producción en el nuevo centro de datos.
En
este punto se puede desarmar el centro de datos de respaldo, con la sección
final del plan indicando la disposición de todo el hardware temporal.
Finalmente, se hace una revisión de la efectividad del plan, integrando
cualquier cambio recomendado por el comité de revisión en una versión actualizada
del plan.
Referencia